apache Kafka چیست؟ و چه کاربردهایی دارد؟ آپاچی کافکا یک پلتفرم توزیع شده برای جریان دادهها است که امکان انتشار، اشتراک، ذخیرهسازی و پردازش جریانهای دیتارِکورد در زمان واقعی را فراهم میکند. این پلتفرم برای مدیریت جریانهای داده از منابع مختلف و ارسال آنها به مخاطبین متعدد طراحی شده است. اگر بخواهیم کار Apache Kafka را به صورت خلاصه بیان کنیم، میتوانیم اینطور بگوییم که این پلتفرم، حجم عظیمی از داده را از هر نقطه به نقاط مختلف دیگر به صورت همزمان منتقل میکند.
آپاچی کافکا به عنوان جایگزینی برای سیستمهای پیامرسانی سازمانی سنتی مطرح شده است. این پلتفرم ابتدا به عنوان یک سیستم داخلی در لینکدین برای مدیریت 1.4 تریلیون پیام در روز توسعه یافت، اما اکنون به یک راهحل متن باز برای جریان دادهها با کاربردهای متنوع در نیازهای سازمانی تبدیل شده است.
Apache Kafka چیست؟
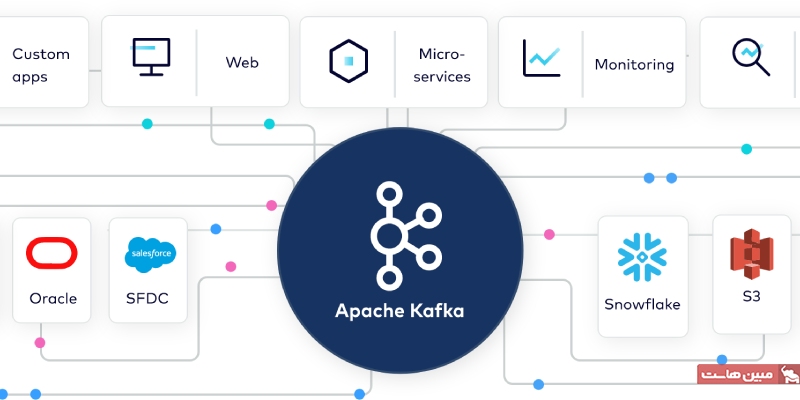
آپاچی کافکا را میتوانیم یک سامانه دادهی توزیعشده در نظر گرفت که برای دریافت و پردازش دادههای در جریان به صورت بلادرنگ، بهینه شده است. دادههای در جریان (streaming data)، به دادههایی گفته میشود که به طور مداوم توسط هزاران منبع مختلف تولید میشوند. این منابع، به طور همزمان رکوردهای داده را ارسال میکنند. یک پلتفرم پردازش داده نیازمند مدیریت این حجم انبوه و پیوسته اطلاعات است و باید بتواند این دادهها را به صورت ترتیبی و مرحلهای پردازش نماید.
کافکا سه قابلیت اصلی را در اختیار کاربران خود قرار میدهد:
- انتشار و اشتراک جریانهای داده
- ذخیره و بهینه سازی جریان رکوردهای داده به ترتیب تولید آنها
- پردازش جریانهای داده به صورت بلادرنگ در زمان واقعی
کافکا به طور عمده برای ساخت گذرگاه یا پایپلاین دادههای در جریان و برنامههایی که با جریانهای دادهای سازگار هستند، مورد استفاده قرار میگیرد. این پلتفرم با ترکیب پیامرسانی، ذخیرهسازی و پردازش جریان داده، امکان ذخیرهسازی و تحلیل دادههای تاریخی و به صورت همزمان را فراهم میکند.
نحوه کار Apache Kafka به چه صورت است؟
در این قسمت از آموزش Apache Kafka سه قابلیت اصلی این سیستم را معرفی میکنیم:
- برنامهها را قادر میسازد تا دادهها یا جریانهای رویداد را منتشر و یا به آنها اشتراک شوند.
- رکوردها را به طور دقیق و به ترتیب رخ دادن، به یک روش fault-tolerant و بادوام، ذخیره میکند.
- رکوردها را همزمان با وقوع آنها پردازش میکند.
توسعه دهندگان و برنامه نویسان میتوانند از طریق چهار API، از هر سه قابلیت کافکا استفاده کنند. این APIها عبارتند از:
- Producer API: این API به یک برنامه اجازه میدهد تا جریانی از دادهها را در یک “Topic” کافکا منتشر کند. Topic یک لاگ نامگذاری شده است که رکوردها را به ترتیب وقوعشان نسبت به یکدیگر نگهداری میکند. پس از نوشتن یک رکورد در یک Topic، امکان تغییر یا حذف آن وجود ندارد. بلکه در Topic برای مدت زمان پیشتنظیم شده (مثلا دو روز) یا تا زمانی که فضای ذخیرهسازی تمام شود، باقی میماند.
- Consumer API: این API به یک برنامه اجازه میدهد تا در یکی یا چند مورد از Topicها مشترک شود و جریان ذخیرهشده در آن را دریافت و پردازش کند. این API میتواند در زمان واقعی روی رکوردها در یک Topic کار کند، یا رکوردهای گذشته را دریافت و پردازش کند.
- Streams API: این API بر اساس APIهای تولیدکننده و مصرفکننده ساخته شده است و قابلیتهای پردازش پیچیدهای را به برنامه اضافه میکند. این API به یک برنامه اجازه میدهد تا پردازش مستمر و کامل (front-to-back) جریان رکوردها را انجام دهد. به طور خاص، این API مجوز مصرف رکوردها از یک یا چند Topic، تجزیه و تحلیل، جمعآوری، تغییر آنها و همچنین انتشار جریانهای خروجی به همان Topic یا دیگر Topicها را میدهد. در حالی که APIهای Producer و Consumer برای پردازش ساده جریان استفاده میشوند، این Stream SPI است که توسعه برنامههای پیچیدهتر داده و رویداد-جریان را ممکن میسازد.
- Connector API: این API به توسعهدهندگان اجازه میدهد تا اتصالدهندههایی بسازند که producer یا consumerهای قابل استفاده مجدد هستند و یکپارچهسازی منبع داده را در یک خوشه کافکا ساده و خودکارسازی میکنند.
عملکرد Apache Kafka

آپاچی کافکا یک پلتفرم توزیع شده است، به این معنی که مانند یک خوشه هماهنگ از سرورها کار میکند که میتوانند در چندین سرور و حتی در چندین دیتاسنتر مختلف پراکنده باشند. این ویژگی باعث میشود کافکا در برابر خطا مقاوم بوده و همواره در دسترس باشد.
یکی از نقاط قوت کافکا مقیاس پذیری آن است. دادههای کافکا در بخشهای کوچکتری به نام پارتیشن (Partition) تقسیم شده و این پارتیشنها در چند سرور به صورت کپی وجود دارند (تکثیر یا Replication). این یعنی اگر یک سرور از دسترس خارج شود، دادهها همچنان روی دیگر سرورها موجود هستند و جریان داده قطع نمیشود. همچنین با اضافه کردن سرورهای بیشتر، میتوان ظرفیت پردازش و ذخیرهسازی کافکا را افزایش داد تا حجم بیشتری از داده را مدیریت کند.
این طراحی باعث میشود کافکا بتواند از پس تعداد زیادی از consumer همزمان بربیاید، بدون اینکه بر عملکرد آن تأثیر گذاشته شود. همانطور که وبسایت Apache.org اعلام میکند، «عملکرد کافکا چه 50 کیلوبایت فضای ذخیرهسازی داشته باشد، چه 50 ترابایت، تفاوتی نمیکند».
کاربردهای Apache Kafka چیست؟

در درجهی اول، از آپاچی کافکا برای دو کاربرد اصلی استفاده میشود:
- پایپلاینهای استریم بلادرنگ: این نوع برنامهها به طور خاص برای انتقال میلیونها و میلیونها دیتارِکورد یا رخداد بین سیستمهای سازمانی در مقیاس بزرگ و به صورت لحظهای، و همچنین انتقال آنها به طور قابل اعتماد و بدون ریسک خرابی، تکثیر داده و سایر مشکلاتی که به طور معمول هنگام انتقال چنین حجم عظیمی از داده با سرعت بالا رخ میدهد، طراحی شدهاند.تصور کنید سیستمی دارید که دادههای فروش، موجودی انبار و تراکنشهای مالی را از صدها فروشگاه در سراسر کشور در زمان واقعی جمعآوری میکند. پایپلاین دادههای جریانی مبتنی بر کافکا میتواند به طور یکپارچه این دادهها را از منابع مختلف استخراج کند، آنها را پردازش و فیلتر کند و سپس به سیستمهای تحلیلی یا داشبوردهای مدیریتی تحویل دهد. این کار به شما امکان میدهد تصمیمگیریهای لحظه ای بر اساس دادههای به روز را انجام دهید.
- برنامههای استریم بلادرنگ: این نوع برنامهها توسط جریانهای دیتارِکورد یا رخداد هدایت میشوند و جریانهای خاص خود را تولید میکنند. اگر هر روز از اینترنت استفاده میکنید، به احتمال زیاد در طول روز با تعداد زیادی از این برنامهها مواجه میشوید، از وبسایتی که به طور مداوم تعداد موجودی یک محصول در فروشگاه محلی شما را بهروزرسانی میکند تا وبسایتهایی که توصیههای شخصی یا تبلیغات را بر اساس تجزیه و تحلیل جریان کلیک نمایش میدهند. به عنوان مثال، یک برنامه چت مبتنی بر کافکا میتواند جریان پیامهای جدید، وضعیت آنلاین کاربران و رویدادهای دیگر را پردازش کند تا تجربه کاربری روان و همزمان را برای همه شرکتکنندگان در چت فراهم کند.کافکا با امکان مقیاسپذیری، تحمل خطا و پردازش بلادرنگ دادهها، ابزار قدرتمندی برای ایجاد این نوع برنامههای کاربردی است که نیازمند واکنش سریع به تغییرات لحظه ای در دادهها هستند.
سایر کاربردهای کافکا عبارتند از:
گذرگاه داده
در بستر آپاچی کافکا، گذرگاه داده یا پپایپ لاین دادههای جریانی به معنای دریافت دادهها از منابع مختلف به محض تولید و سپس ارسال آن دادهها از کافکا به یک یا چند مقصد است. این کار معمولا به صورت بلادرنگ و پیوسته (streaming) انجام میشود.
پردازش جریان داده
پردازش جریان داده شامل عملیات مختلفی مانند فیلتر، پیوستها، مپها و سایر کارهایی میشود که سازمانها از آنها برای پشتیبانی از کاربریهای متعدد بهره میگیرند. Kafka Streams یک کتابخانه پردازش جریانی ساخته شده برای آپاچی کافکا است که به سازمانها امکان میدهد دادهها را به صورت بلادرنگ پردازش کنند.
تجزیهوتحلیل جریان داده
کافکا انتقال رویدادها با حجم بالا را امکان پذیر میکند و زمانی که با فناوریهای متن باز مانند Druid ترکیب شود، میتواند یک مدیریت قدرتمند تجزیه و تحلیل جریان داده (SAM) را تشکیل دهد. Druid دادههای استریم را از کافکا دریافت میکند تا کوئریهای تحلیلی را فعال کند. ابتدا رویدادها در کافکا بارگذاری میشوند، جایی که قبل از مصرف توسط مصرفکنندگان بلادرنگ Druid، در کارگزاران کافکا (Kafka brokers) بافر میشوند.
استریم ETL
ETL بلادرنگ با کافکا، اجزا و ویژگیهای مختلفی مانند اتصالات منبع و مقصد کافکا Connect را برای مصرف و تولید داده از/به هر پایگاه داده، برنامه یا API دیگر، تبدیل تک پیام (SMT) برای پردازش مداوم داده در مقیاس بزرگ و بلادرنگ را با هم ترکیب میکند.
میکروسرویسهای رویداد-محور
آپاچی کافکا محبوبترین ابزار برای میکروسرویسها است زیرا بسیاری از مسائل مربوط به هماهنگسازی و یکپارچگی میکروسرویسها را حل میکند، در عین حال امکان دستیابی به ویژگیهایی را فراهم میسازد که میکروسرویسها به دنبال آن هستند، مانند مقیاسپذیری، کارایی و سرعت. همچنین امکان برقراری ارتباط بین سرویسها را با حفظ تأخیر فوق العاده کم و تحمل خطا فراهم میکند.
کافکا برای چه کاربردهایی مناسب نیست؟
همانطور که در بخش قبل دیدیم، آپاچی کافکا برای استفاده از یک سری کاربردها مناسب است؛ اما این به این معنی نیست که در همه جا کاربرد دارد. موارد استفادهای که توصیه نمیشود یا نمیتوانید از کافکا استفاده کنید، عبارتنداز:
- پروکسی میلیونها مشتری برای برنامههای تلفن همراه یا اینترنت اشیا: کافکا به طور خاص برای این منظور طراحی نشده است، اما راهحلهایی برای تسهیل ارتباط با وجود این محدودیت وجود دارد.
- پایگاه داده با ایندکس (index): کافکا در اصل یک سیستم ثبت رویدادهای استریم است و امکانات تحلیلی پیشرفته یا مدل کوئری پیچیدهای ندارد.
- فناوری بلادرنگ تعبیهشده برای اینترنت اشیا: گزینههای دیگری با سطح پیچیدگی و مصرف منابع کمتر برای این منظور در دسترس هستند.
- صفهای کاری: کافکا به جای صف (مانند RabbitMQ، ActiveMQ و SQS) از موضوعات (topics) استفاده میکند. صفها برای مقیاسپذیری میلیونها مصرفکننده و حذف پیامها پس از پردازش طراحی شدهاند. در کافکا، دادهها پس از پردازش حذف نمیشوند و تعداد مصرفکنندگان محدود به تعداد پارتیشنهای یک موضوع است.
- کافکا به عنوان یک بلاکچین: موضوعات کافکا برخی شباهتهایی با بلاکچین از نظر ثبت ترتیبی دادهها و عدم تغییرپذیری دارند، اما از ویژگیهای کلیدی بلاکچین مانند تایید رمزنگاری دادهها و حفظ کامل تاریخچه محروم هستند. به همین دلیل، توصیه میشود که از کافکا به عنوان بلاکچین استفاده نکنید.
تکنولوژیهای مورد استفاده در apache kafka

معمولا، آپاچی کافکا همراه با فناوریهای دیگر apache برای پردازش استریمهای بزرگتر معماری رویداد-محور و یا تجزیهوتحلیل دادههای بزرگ استفاده میشود. برخی از تکنولوژیهای مورداستفاده در این سیستم عبارتند از:
Apache Spark
اسپارک یک موتور تحلیلی برای پردازش دادههای با حجم بالا است. شما میتوانید از اسپارک برای تجزیه و تحلیل جریانهای تحویل داده شده توسط آپاچی کافکا و ایجاد برنامههای پردازش جریان داده بلادرنگ مانند تجزیه و تحلیل کلیکاستریم (click-stream) استفاده کنید.
Apache NiFi
NiFi یک سیستم مدیریت جریان داده با یک رابط کاربری درگ/دراپ بصری است. از آنجایی که NiFi میتواند به عنوان یک consumer و producer کافکا اجرا شود، ابزار ایدهآلی برای مدیریت چالشهای جریان دادههایی است که کافکا نمیتواند آنها را برطرف کند.
Apache Flink
فلینک یک موتور برای انجام محاسبات روی جریانهای رویداد در مقیاس بزرگ با سرعت بالا و تأخیر کم است. فلینک میتواند جریانها را به عنوان یک consumer کافکا دریافت کند، عملیات مبتنی بر این جریانها را به صورت بلادرنگ انجام دهد و نتایج را در کافکا یا برنامه دیگری منتشر کند.
Apache Hadoop
هادوپ یک چارچوب نرمافزاری توزیعشده است که به شما امکان میدهد مقادیر عظیمی از داده را در یک خوشه از رایانهها برای استفاده در تحلیل دادههای بزرگ، یادگیری ماشین، استخراج داده و سایر برنامههای کاربردی مبتنی بر داده که دادههای ساختار یافته و بدون ساختار را پردازش میکنند، ذخیره کنید. کافکا اغلب برای ایجاد یک پایپلاین دادههای استریم به صورت بلادرنگ به یک خوشه هادوپ استفاده میشود.
مزایای Apache Kafka چیست؟

همانطور که تا الان متوجه شدهاید، آپاچی کافکا مزایای فراوانی دارد. در حال حاضر، این سیستم توسط بیش از 80% از صنایع بزرگ تا کوچک در سراسر جهان استفاده میشود. توسعه دهندگان و معماران میتوانند از این فناوری برای ساخت جدیدترین نسل برنامههای کاربردی جریان دادهی مقیاس پذیر و بلادرنگ استفاده کنند. با این که این ویژگیها را میتوانید با استفاده از طیف وسیعی از فناوریهای موجود در بازار بدست آورید، اما برخی از مزایای کافکا باعث شده که محبوبیت آن بیشتر از سایر فناوریها باشد. این مزایا عبارتند از:
قدرت عملیاتی بالا
کافکا میتواند با دادههای ورودی و خروجی حجیم و با سرعت بالا کار کند و قادر به مدیریت میلیونها پیام در ثانیه است.
مقیاسپذیری بالا
خوشههای کافکا را میتوان تا هزاران کارگزار (broker)، پردازش تریلیونها پیام در روز، پتابایتها داده و صدها هزار پارتیشن گسترش داد. همچنین ظرفیت ذخیرهسازی و پردازش میتواند به صورت پویا افزایش یا کاهش یابد.
تاخیر بسیار کم
کافکا توانایی تحویل حجم عظیمی از پیامها با استفاده از یک خوشه از ماشینها با تأخیر کم تا ۲ میلیثانیه را دارد.
ذخیرهسازی دائمی
کافکا میتواند جریانهای دادهها را در یک خوشه توزیعشده، مقاوم و دارای تحملپذیری خطا به صورت ایمن، مطمئن و بادوام ذخیره کند.
دسترسی بالا
گسترش کارآمد خوشهها در سراسر مناطق در دسترس یا اتصال خوشهها در مناطق جغرافیایی مختلف، که باعث میشود کافکا در دسترسپذیری بالا و تحملپذیری خطا بدون خطر از دست رفتن دادهها باشد.
نقش Kubernetes در گسترش مقیاس برنامههای Apache Kafka

Kubernetes یک پلتفرم ایده آل برای کافکا به شمار میرود. توسعه دهندگان برای مزبانی برنامههای کافکا به یک پلتفرم مقیاس پذیرjv نیاز دارند و Kubernetes میتواند این نیاز را به بهترین شکل ممکن برطرف کند.
Kubernetes مانند کافکا میتواند روند توسعهی برنامه را راحتتر و هموارتر کند. این سیستم که یک فناوری پشت سرویسهای ابری گوگل است، یک سیستم منبع باز برای مدیریت برنامههای کانتینری فراهم میکند و با خودکارسازی، نیاز به انجام بسیاری از فرایندهای دستی کانتینری را از بین میبرد. استفاده از آپاچی کافکا در Kubernetes میتواند به سادهترکردن استقرار، پیکربندی و مدیریت کافکا کمک کند.
با ترکیب این دو فناوری، شما میتوانید به طور همزمان از تمام مزایای کافکا و Kubernetes مانند مقایسپذیری، دسترسی بالا، قابلیت حمل و استقرار آسان بهرهمند شوید.
ویژگی مقیاسپذیری Kubernetes میتواند به عملکرد بهتر کافکا کمک کند. در Kubernetes، فقط با یک دستور ساده میتوانید منابع موردنیازتان را کمتر یا بیشتر کنید و یا سیستم را طوری تنظیم کنید که بر اساس میزان مصرفتان، منابع به صورت خودکار تخصیص داده شوند. با استفاده از این قابلیت، کافکا میتواند مجموعهی محدودی از منابع را با سایر برنامهها به اشتراک گذاشته و بدین صورت، شما میتوانید بهترین استفاده را از زیرساختهای محاسباتی، شبکه و ذخیرهسازی داشته باشید.
همچنین، Kubernetes قابلیت جابجایی آپاچی کافکا را در ارائهدهندگان زیرساخت و سیستم عاملهای مختلف فراهم میکند. . با استفاده از Kubernetes، خوشههای Apache Kafka میتوانند بین ابرهای محلی و عمومی، خصوصی یا ترکیبی گسترش یابند و از سیستمهای عامل مختلف استفاده کنند.
مثالهایی از کاربرد آپاچی کافکا

از آپاچی کافکا به طور گستردهای در صنایع مختلف استفاده میشود. در این بخش، برخی از مهمترین موارد استفاده از این فناوری را عنوان میکنیم…
شرکت اوبر از کافکا برای گذرگاه قیمتگذاری بلادرنگ خود استفاده میکند. در واقع، کافکا ستون فقراتی است که از طریق آن، بخش قابلتوجهی از رویدادها به قسمت محاسبات پردازش استریمهای مختلف، منتقل میشوند. کافکا با سرعت و انعطافپذیری بالای خود، اوبر را قادر میسازد تا مدلهای قیمتگذاریاش را با رویدادهایی که در دنیای واقعی دائما در حال تغییر هستند، تنظیم کرده و مبلغ مناسبی را برای کاربران به صورت قبض منتشر کند.
مثال دیگر استفاده از کافکا در دنیای واقعی، نتفلیکس است. شرکت نتفلیکس، کافکا را به عنوان جزء اصلی پلتفرم دادهی خود، ادغام کرده است. این شرکت، از کافکا به عنوان گذرگاه دادهی Keystone اشاره میکنند. کافکا به عنوان بخشی از Keystone نتفلیکس، روزانه میلیاردها رویداد را به صورت خودکار مدیریت میکند. در واقع، نتفلیکس چیزی در حدود 500 میلیارد رویداد و 1.3 پتابایت داده را در طول روز به کافکا ارسال میکند.
مثالها و موارد استفادهی بیشماری از کافکا در دنیای واقعی وجود دارد. در واقع، آپاچی کافکا هستهی اصلی بسیاری از عملیاتی است که ما روزانه با آنها سروکار داریم. برخی از بزرگترین شرکتهای فناوری جهان که از کافکا استفاده میکنند عبارتند از Apple، Airbnb، LinkedIn، Walmart و غیره…
آموزش Apache Kafka؛ مبانی اولیه
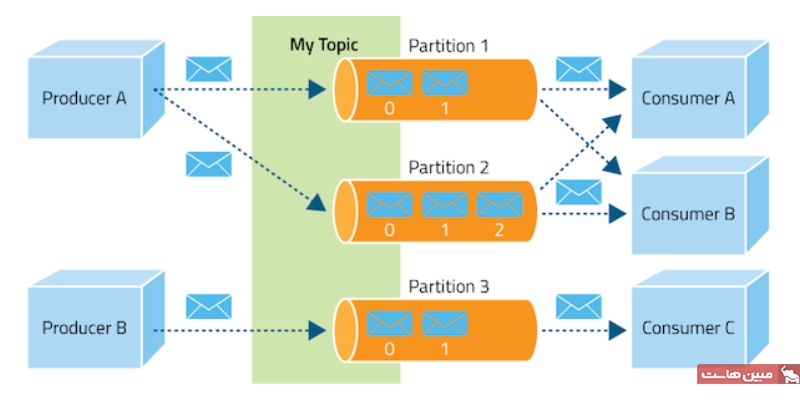
اکنون که با مفاهیم کلی آپاچی کافکا آشنا شدیم، به سراغ نحوه استفاده از این ابزار قدرتمند میرویم. در این بخش، اصول اولیه موضوعات (Topics)، تولیدکنندگان (Producers) و مصرفکنندگان (Consumers) کافکا را بررسی میکنیم.
- Kafka Topic:
موضوعات کافکا، رویدادهای مرتبط را سازماندهی میکنند. برای مثال، ممکن است موضوعی به نام logs داشته باشیم که حاوی گزارشهای کاربردی است. موضوعات تقریباً مانند جداول SQL عمل میکنند، با این تفاوت که قابل پرسوجو (Query) نیستند. برای استفاده از دادههای درون موضوعات، باید تولیدکنندگان و مصرفکنندگان کافکا را ایجاد کنیم. دادههای موضوعات به صورت کلید-مقدار و در قالب باینری ذخیره میشوند. - Kafka Procedure:
پس از ایجاد یک موضوع در کافکا، گام بعدی ارسال داده به آن است. برنامههایی که دادهها را به یک Topic ارسال میکنند، به عنوان تولیدکنندگان کافکا شناخته میشوند. روشهای مختلفی برای تولید رویداد به کافکا وجود دارد، اما به طور معمول، برنامهها با کتابخانههای کلاینت کافکا به زبانهای جاوا، پایتون، Go و سایر زبانها ادغام میشوند.
- Kafka Consumer:
پس از ایجاد موضوع و ارسال داده به آن، میتوانیم برنامههایی را داشته باشیم که از جریان داده استفاده کنند. برنامههایی که دادههای رویداد را از یک یا چند موضوع کافکا دریافت میکنند، به عنوان مصرفکنندگان کافکا شناخته میشوند. روشهای مختلفی برای مصرف رویدادها از کافکا وجود دارد، اما به طور معمول، برنامهها با کتابخانههای کلاینت کافکا به زبانهای جاوا، پایتون، Go و سایر زبانها ادغام میشوند. به طور پیشفرض، مصرفکنندگان فقط دادههایی را مصرف میکنند که پس از اتصال اولیه مصرفکننده به موضوع تولید شدهاند.
مقایسه Apache Kafka و RabbitMQ

RabbitMQ یک رابط پیام متن باز بسیار محبوب است که به عنوان یک نرمافزار واسط عمل میکند و امکان برقراری ارتباط بین برنامهها، سیستمها و سرویسها با ترجمه پروتکلهای پیامرسانی بین آنها را فراهم میکند.
از آنجایی که کافکا در ابتدا به عنوان نوعی رابط ارتباطات پیام (و به لحاظ تئوری هنوز هم میتواند به عنوان چنین سیستمی مورد استفاده قرار گیرد) و ربیتامکیو از الگوی پیامرسانی انتشار/اشتراک (در کنار سایر الگوها) پشتیبانی میکند، این دو سیستم اغلب به عنوان گزینههای جایگزین با هم مقایسه میشوند.
اما این مقایسهها چندان کاربردی نیستند و اغلب به جزئیات فنی دقت زیادی مبکنند که هنگام انتخاب بین این دو مورد چندان مهم نیستند. به عنوان مثال، این که موضوعات کافکا میتوانند مشترکین متعدد داشته باشند، در حالی که هر پیام ربیتامکیو فقط میتواند یک مشترک داشته باشد؛ یا این که موضوعات کافکا ماندگار و دائمی هستند، در حالی که پیامهای رابیتمک کیو پس از مصرف حذف میشوند.
نکته اصلی این است که:
- آپاچی کافکا یک پلتفرم پردازش جریان داده است که به برنامهها امکان میدهد حجم زیادی از جریانهای رکورد را به روشی سریع و بادوام منتشر، استفاده و پردازش کنند.
- RabbitMQ یک رابط پیام است که به برنامههای کاربردی با پروتکلهای پیامرسانی مختلف امکان میدهد پیامها را برای هم ارسال و از هم دریافت کنند.
جمعبندی
در این مطلب به بررسی جامع این که apache kafka چیست و کاربردها و مزایای آن پرداختیم. آپاچی کافکا یک پلتفرم قدرتمند و انعطافپذیر برای پردازش جریان داده است که میتواند برای طیف گستردهای از کاربردها مورد استفاده قرار گیرد. اگر به دنبال راه حلی برای پردازش حجم عظیمی از دادهها به صورت سریع، مقیاسپذیر و بادوام هستید، کافکا میتواند گزینهای ایدهآل برای شما باشد.